為什麼你需要 Adobe PDF Extract API?
在處理數位文件時,我們常遇到結構複雜的 PDF,例如內嵌表格、多欄位排版或圖片資訊。一般的 PDF 轉文字工具往往會導致格式亂掉,使得後續的資料分析變得困難。Adobe PDF Extract API 利用 AI 技術,能精準提取 PDF 中的結構化數據(JSON 格式),保留表格與文字的關聯性 。結合 n8n 自動化平台,你可以打造出一套完全自動化的文件處理流程,大幅節省人工登打的時間。
從雜亂 PDF 到結構化資料
透過本教學配置後,你將獲得一個強大的自動化工作流:
- 全自動認證:無需手動點擊,系統自動處理 Token 換證 。
- 非同步處理:自動完成檔案上傳、提取任務提交與進度輪詢 。
- 結構化輸出:最終產出精確的 JSON 資料,可直接用於 Notion、Google Sheets 或資料庫 。
細節說明與手把手教學
Adobe PDF Extract API 採用「非同步(Asynchronous)」流程,操作上可分為六大關鍵階段:
第一步、申請Adobe PDF Extract API(已申請可跳過)
1.開啟Adobe Developer Console,若無帳號需建立一組,若有帳號請登入。
2.點選「Launch Adobe Developer Console」啟用開發者控制台。
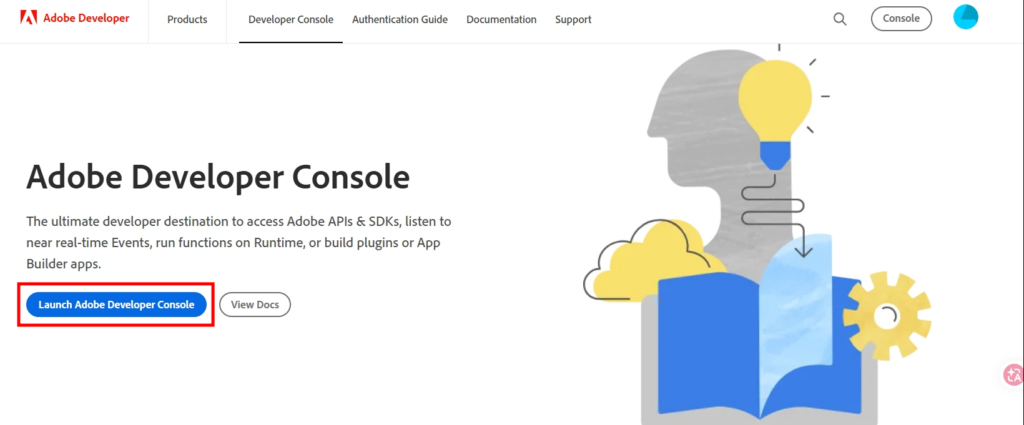
3.建立一個新的專案
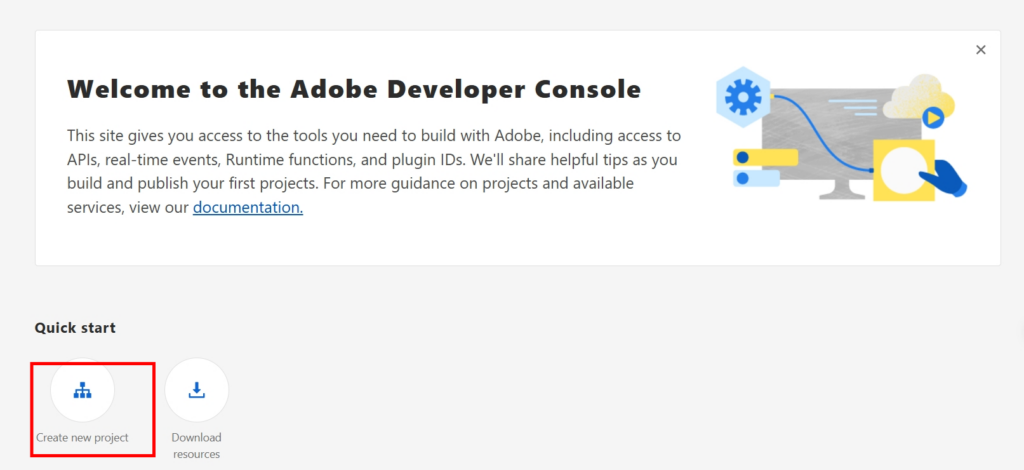
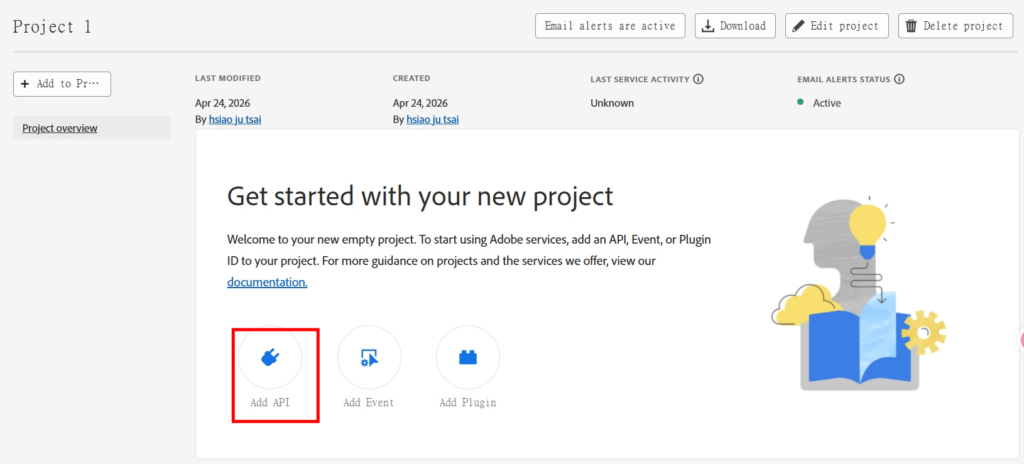
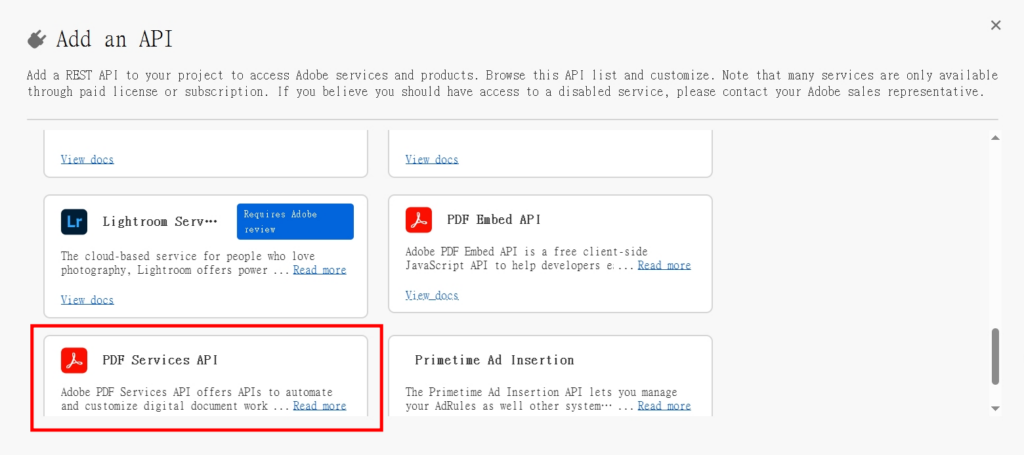
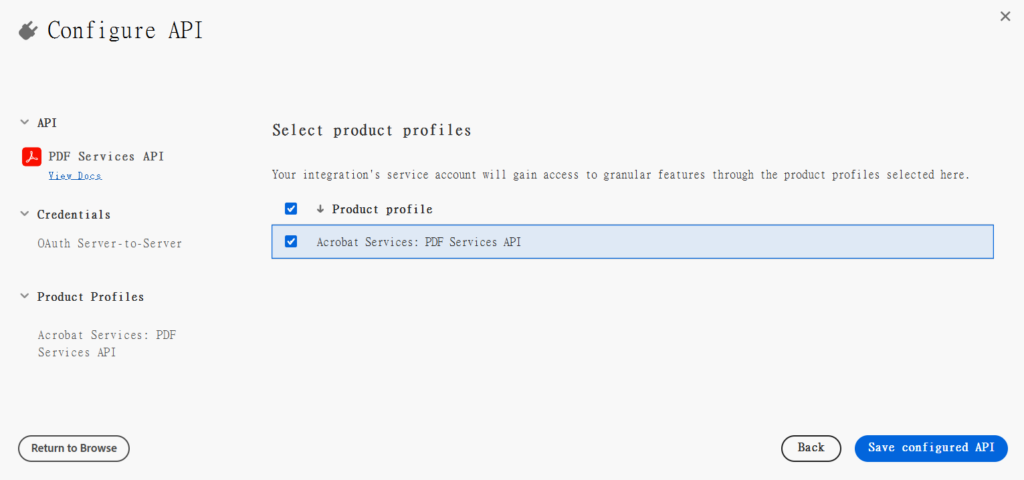
4.增加一個API,並選取「PDF Services API」
5.開啟Oauth Server to Server,並取一個你知道的名稱
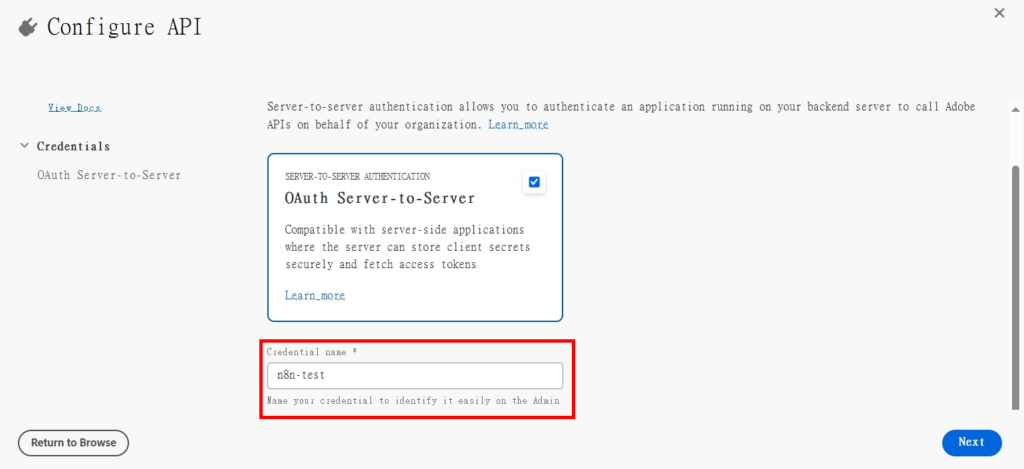
6.選擇要開啟的產品,這邊只有開啟「PDF Services API」
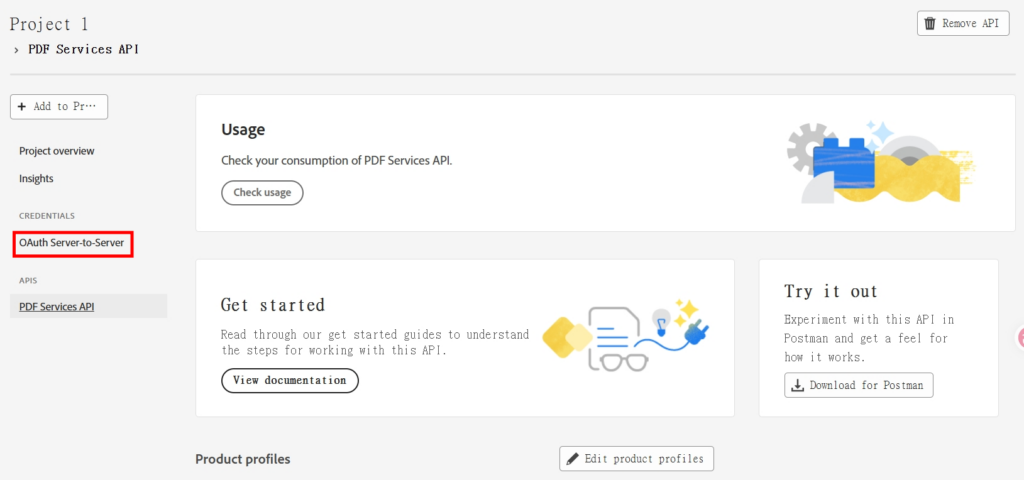
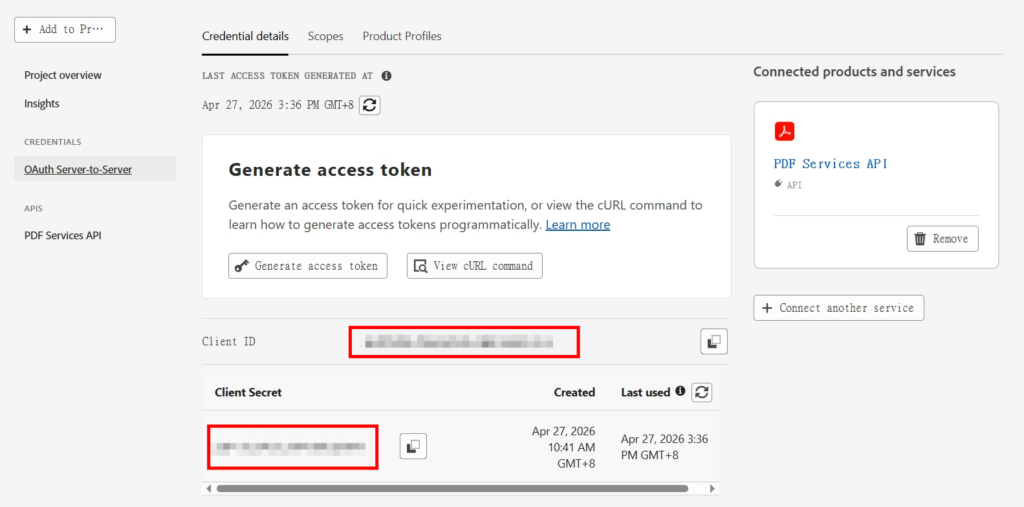
7.成功開啟後,選「Oauth Server to Server」取得「Client ID」及「Client Secret」
第二步、獲取 Access Token(自動化鑰匙)
1.HTTP Request 節點配置
回到n8n,在任何一個工作流,建立一個「HTTP Request」節點。

節點設定內容如下:
- Method:
POST - URL:
https://pdf-services.adobe.io/token - Authentication:
None - Send Body:開啟
- Body Content Type:
Form-Urlencoded - Specify Body:Using Fields Below
- Body Fields
client_id:你的 Client IDclient_secret:你的 Client Secret
第三步、取得臨時暫存位置
PDF 檔案不能直接丟給Adobe PDF Extract API 做提取動作,必須先取得「暫存位址」,再開啟一個新的Http Request節點。
節點設定如下:
- Method:
POST - URL:https://pdf-services.adobe.io/assets
- Authentication:
None - Send Headers:開啟
- Specify Headers:
Using Fields Below - Headers:
Authorization:上一個節點取得的access tokenx-api-key:你的 Client ID
第四步、上傳檔案
先利用一個Merge將上傳的檔案及取得上傳的網址做合併(用Combine),確保「上傳網址」與「檔案內容」能同時傳遞到下一個節點 。
再建立一個Http Request節點做上傳檔案的動作。節點設定如下:
- Method:
PUT - URL:{{ $json.uploadUri }} (前一個節點取得的URL)
- Authentication:
None - Send Headers:開啟
- Specify Headers:
Using Fields Below - Headers:
Content-Type:application/pdf
- Send Body:開啟
- Body Content Type:
n8n Binary File- Input Data Field Name:data (這部份要看你檔案命名的方式調整,預設是使用data)
第五步、啟動提取與輪詢
上傳成功後,下令讓 AI 開始分析,這部份會需要花時間等待(依檔案的內容處理時間不定),所以需要設定一個迴圈,讓他自動偵測是否回傳「done」。
設定等待時間:加入 Wait 節點(建議 10 秒),避免太快查詢導致失敗。
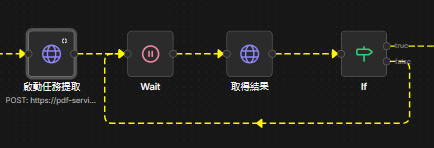
啟動任務提取Http Request節點設定如下:
- Method:
POST - URL:https://pdf-services.adobe.io/operation/extractpdf
- Authentication:
None - Send Headers:開啟
- Specify Headers:
Using Fields Below - Headers:
Authorization:前面取得的access token- x-api-key:你的 Client ID
- Content-Type:application/json
- Send Body:開啟
- Body Content Type:JSON
- Specify Body:Using JSON
- JSON:
{
"assetID": "{{ $node["獲取上傳地址"].json["assetID"] }}",
"elementsToExtract": ["text", "tables"]
}- Add Options建立一個Response
- Include Respose Headers and Status:開啟
取得結果Http Request節點設定如下:
- Method:
GET - URL:{{ $node[“啟動任務提取”].json[“headers”][“location”] }}
- Authentication:
None - Send Headers:開啟
- Specify Headers:
Using Fields Below - Headers:
Authorization:前面取得的access token- x-api-key:你的 Client ID
第六步、下載與解析結果
最後,查詢任務狀態直到顯示為「done」代表已完成分析,可以透過下載取得最後資料,並透過解壓縮、篩選及轉換,將最終的文字內容解析呈現

下載解析後檔案Http Request節點設定如下:
- Method:
GET - URL:{{ $json.resource.downloadUri }}
- Authentication:
None - Options:建立Response
- Response Format:File
- Put Output in Field:data
結語
在使用 Adobe PDF Services API(包含 Extract API)時,請留意以下規則:
- 每月免費額度:目前官方提供的免費層級(Free Tier)為 每個月 500 次免費交易。
- 什麼是「一次交易」?:
- Adobe 的計費中,是按「次」而非單純按「頁」計算。
- 通常一次成功的 API 請求(例如提取一份 PDF)算作 1 次 Transaction。
- 注意:如果文件頁數非常多(例如超過一定頁數限制),可能會折算為多次 Transaction,具體取決於當時的服務條款。
- 什麼是「一次交易」?:
- 檔案上限:
- 檔案大小:單個檔案通常上限為 100 MB。
- 頁數上限:單次處理建議不超過 200 頁(為了確保 AI 解析的準確度與穩定性)。
- Token 有效期:產生的 Access Token 有效期為 24 小時。在 n8n 流程中,建議設定「自動重新獲取」的機制,確保流程不會斷掉。